


This is the second blog in the series Machine Translation: An Overview by Dr. S. K. Srivastava.
The language barrier is a universal problem. Language translation is not only important for trade and commerce but, is needed for education, governance, national unity, and international relations, etc. Before we discuss the national scenario, it is worth taking a look at the international scenario. Broadly, we can divide the developments into three phases – early phase, mid-phase, and recent phase.
Early Phase
The research in MT started way back in the late forties of the last century. The memorandum of Warren Weaver written in 1949 was one of the first publications in machine translation. Several academic institutions like MIT, University of Washington, University of Georgetown, University of London had teams working in this area. A conference on machine translation was held in MIT in 1952. A public demonstration of machine translation was made by a joint team of the University of Georgetown and IBM in 1954. The reasons behind the interests of the countries in machine translation varied from country to country. In the United States, most of the funding was provided by the Department of Defense as it was interested in automating the translating of the documents from Russian to English due to the ongoing cold war. Canada was interested in machine translation as it wanted translation between its two official languages - English and French. European Union wanted it for building a single economy while allowing people to use their native languages. Some countries like Japan and China were interested in translation as they felt it necessary for growth in international trade and commerce.
As it happens in any emerging technology, there have been ups and downs in this area as well. When Automatic Language Processing Advisory Committee (ALPAC) formed by the US Government, submitted its report on the state of MT in 1966, it observed that the research had not fulfilled the expectations. This led to a substantial reduction in funding. However, another report published in 1972 by the Director of Defense Research and Engineering appreciated the performance of the Logos MT system in translating military manuals into Vietnamese during the conflict. Other countries too have been going through similar experiences.
Despite all the efforts made by researchers across the world, a perfect translator between two languages has not yet been built. The main difficulty in language translation is that translation is not just a mechanical activity but requires contextual knowledge, commonsense reasoning, and language skills of the domain. The underlying problem is language comprehension which is needed during translation. The task of language comprehension has been known as a tough problem since the very beginning of the computer era and that is why when Alan Turing described the test of machine intelligence in his seminal paper Computing Machinery and Intelligence, it was based on language comprehension.
During the early phase, MT was primarily a rule-based methodology wherein the knowledge of the language is encoded into rules hand-crafted by the linguists. It was called rule-based machine translation (RBMT). Broadly, any MT system follows the analysis-transfer-generation (ATG) process. Given a source language sentence, the MT system analyzes it to figure out the words and their relations with each other. This creates an intermediate structure – an intermediate representation that is then transferred to a similar structure in the target language. Finally, the system uses this intermediate structure to generate the sentence in the target language. In RBMT, there are rules for analysis, for transfer from one language to another and then rules for a generation.
A variation of the RBMT system is an interlingua-based system. It is based on the hypothesis that any sentence in any source language can be transformed into a language-independent representation and this representation can be used to generate the corresponding sentence in the target language. Developing a truly interlingual MT system based on universal principles-based parsing mechanism and language-dependent generation has been difficult. Only UNITRAN (Universal Translator) can be considered an effort in this direction, but it could not be tested widely.
The limitations of RBMT were realized soon. It is practically not possible to create every rule for any source and target language especially when the languages belong to different language families. Simply, there are too many rules when we attempt to do it. There are multiple ways to express the same thing and one has to select one option based on contextual and common-sense knowledge. To handle this, other ways were explored.
Despite the limitations, companies made use of the available RBMT technology and developed applications/services based on this. Systran has been working with the US Government agencies since the sixties. It worked with the US Air Force to develop a translation system in 1968. delivered a translation system to the US Air Force. Systran, the software developed by the company was used by other companies as well. For instance, Xerox used it to translate its technical manuals in 1978.
Mid-Phase
During the eighties, when computational power increased substantially along with a cost reduction, Statistical Machine Translation (SMT) emerged as an alternative. The idea of SMT can be traced to the paper of Warren Weaver published in 1949 but it was not possible to implement it with the limited computational power of the computers available then. In SMT, parallel sentences in the source and target languages are used to learn the associations between the words and phrases. A phrase in the source language may correspond to many phrases in the target language thus leading to the need of using probability with the associations. Given a new sentence, the system finds the corresponding phrases in the target language along with the associated probabilities. A combination of the phrases giving the maximum probability is selected as the translation into the target language.
Another translation paradigm that emerged during the eighties is example-based machine translation (EBMT) which was proposed by Makoto Nagao of Japan. In EBMT, the system learns translation patterns from the given example translation-pairs. Once the system has learned adequate translation patterns, it can apply to any new source language sentence. Thus, it lies somewhere between RBMT and SMT. The translation patterns come from the data (sentence pairs) but identifying the patterns require rules. As it learns the patterns on its own, it is less time-consuming than RBMT. At the same time, this does not require a large volume of data as in the case of SMT.
Both the approaches RBMT and SMT had their advantages/disadvantages and therefore, several hybrid systems were developed making use of both the techniques. The systems differed in the ways the two techniques are combined. In some approaches, rules are used in translation and once the translated sentence has been obtained, a statistical approach is used to adjust/correct the sentences. In other approaches, rules are used in pre-processing as well as post-processing whereas the translation is done using SMT. Figure 1 illustrates how the translation paradigms have progressed with time. Neural machine translation (NMT) is discussed in the next section.
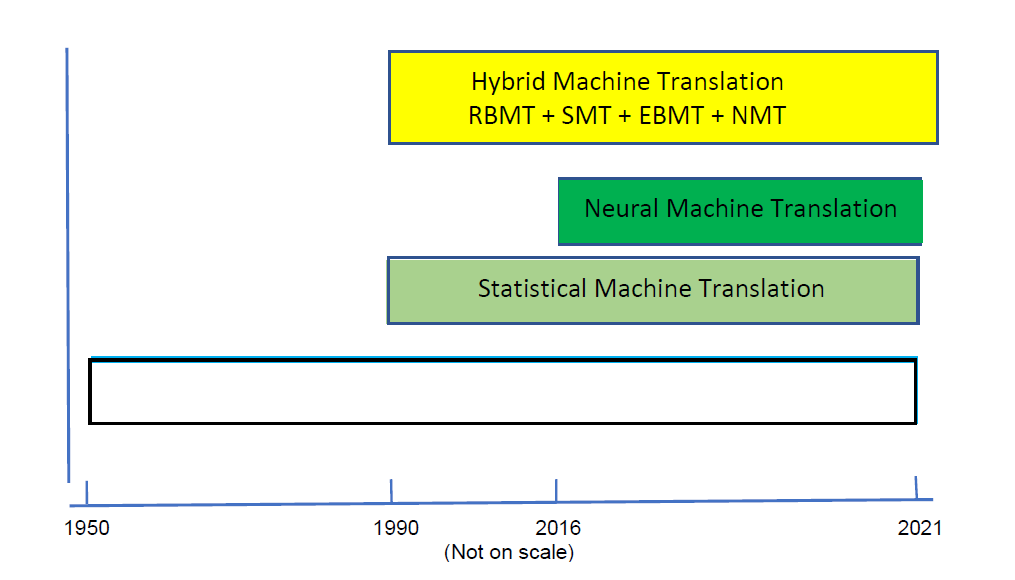
Figure 1: Major Paradigms in Machine Translation
Systran continued to update its software and collaborated with others to provide services. French Postal Service used the Systran system to offer its services in 1988. Systran was the first to offer a free web service for the translation of small texts in 1996. Later, it collaborated with Alta Vista to offer the service through Babel Fish.
From industry, IBM has made the most significant contribution to SMT. One of the first SMT systems was CANDIDE from IBM. The performance of the SMT system depends on the size of the corpus. It was possible to achieve high accuracy where documents were already available in multiple languages. In Canada, good accuracy was achieved using the Canadian Hansard corpus, English - French record of the Canadian parliament. Similarly, European parliament proceedings available in EUROPARL were used to train MT@EC, a system for European languages. The system was built during 2010-2013 and has been operational since 2013. This handled all 24 languages of the European Union (EU). MT@EC was made available free of charge to the public administrators in the member nations.
Google, which was using the Systran system earlier, used United Nations documents available in six languages (Arabic, Chinese, English, French, Russian, and Spanish) to train its SMT system in 2005. With this, it was able to create a dataset of 200 billion words. The system was made available on the web free of cost in 2007. One reason behind the popularity of SMT is the availability of SMT systems in the open-source domain. One such toolkit is Moses, which uses phrase-based SMT and was developed by a team of researchers led by Philipp Koehn of the University of Edinburgh. It was made available in the public domain in 2007. A web-based interface to the Moses has been developed at JNU making it easy to use platform for training SMT for Indian languages. Another is Phrasal which was developed at Stanford University and was made available in an open-source domain in 2010. Several researchers used these toolkits to develop the systems with improved features. Another good SMT model was the Microsoft Translator Hub (MTHub) which has now been migrated to the neural platform.
Recent Phase
After neural network-based processing was successful in computer vision and speech recognition, it was extended to MT as well by the researchers. The improvement in the quality of machine translation based on NMT was significant. Initially, it was developed using sequence-to-sequence models where the sequence is a sequence of words in the source or target language. In the simplest form, NMT is an encoder-decoder system. The encoder takes one word at a time and encodes it to construct a semantic representation. In the end, it generates a semantic representation of the complete sentence. The decoder takes this representation and generates one word at a time in the target language. This was improved using an attention-based mechanism which improved the translation of long sentences.
The research groups working on broader NMT based models developed several models/systems like TensorFlow, seq2seq which have been made available in the open-source domain. In addition to these, some toolkits for production-level NMT have also been made available in the open-source domain. OpenNMT toolkit developed by a joint team of Systran and Harvard University is a popular one. Another example toolkit is Nematus developed at the University of Edinburgh.
The industry was quick to make use of the improved performance provided by neural machine translation and several systems have been developed by Google, Microsoft, Amazon, Facebook, etc. Google Translate moved to NMT from SMT in November 2016. For training the NMT system, it used the parallel text corpus created using the UN documents available in six languages. With time, Google added more and more languages and now it supports 109 languages. However, the quality of the translation varies from the language pair to language pair depending on the parallel or comparable corpus available for the language pair. Google has involved the volunteers who are interested in contributing to making the translator more accurate in the languages of their interest. For that purpose, it has also launched an app that can be used by the volunteers to give their suggestions in terms of corrected translated sentences.
Google Translate can be accessed in several ways – web, mobile app, and API. It has been supporting Indian languages since 2017 and the list of the supported Indian languages has grown to Assamese, Bangla, Gujarati, Hindi, Kannada, Malayalam, Marathi, Nepali, Odia, Sindhi, Tamil, Telugu, and Urdu. Apart from these, the work is continuing for several other languages like Bhojpuri, Maithili, etc.
Microsoft has been providing machine translation services through its product Microsoft Translator (also called Bing Translator) since 2011. It is accessible through API and also through the Microsoft tools like Skype, etc. It supports 103 languages spoken across the world. Users can customize it for their domain. Once customized, it understands the terminologies of the domain. Microsoft has also provided limited speech-to-speech translation services since 2016. For speech translation, it uses speech recognition – text to text translation – text to speech synthesis process.
Microsoft Translator supports the major Indian languages viz. Assamese, Bangla, Gujarati, Hindi, Kannada, Malayalam, Marathi, Nepali, Odia, Punjabi, Tamil, Telugu, Urdu. Some of the Indian institutions have also contributed to this. The English-Urdu MT of Bing Translator has been done with JNU’s collaboration.
(https://www.microsoft.com/en-us/translator/business/community/#JNU)
IBM Watson Language Translator has moved to NMT and supports 54 languages of the world including eight Indian languages viz. Bengali, Gujarati, Hindi, Malayalam, Nepali, Tamil, Telugu, and Urdu. One can create a customized model by training the baseline system with the data of the desired domain. Once trained with the parallel corpus of the domain, it learns the translation styles as reflected in the domain corpus. It can learn new terms and phrases from the glossary of the domain. The translator can be used using APIs.
Amazon Translate is another NMT service that could be accessed in real-time or asynchronous modes. It supports 71 languages including major Indian languages viz. Bengali, Gujarati, Hindi, Kannada, Malayalam, Tamil, Telugu, and Urdu. It can also detect the language if it is not specified. The service can be customized to suit the requirements of the user. Terminologies of the domain can be specified in a custom terminology file. Parallel data can be used to customize the system to reflect the style, tone, and word choices.
Facebook provides translation services to its customers to translate the textual information into the language of their choice. It implemented multilingual machine translation (MMT) which can provide translation between any pair of languages out of more than 100 languages including major Indian languages viz. Assamese, Bangla, Gujarati, Hindi, Kannada, Malayalam, Marathi, Nepali, Odia, Punjabi, Sindhi, Tamil, Telugu, and Urdu. In contrast to other translation services, it is not English-centric i.e. it does not first translate to English and then from English to the target language. The translation capability is helping the businesses to reach the markets where language has remained a barrier. The system has been developed using 7.5 billion sentence pairs gathered from the web. Unlike Amazon, Google, etc., it does not offer standalone translation services.
Globally, several successful machine-aided translation systems have been developed and deployed by organizations in the recent past. One of the biggest users of machine translation is the European Union. It has been funding projects in machine translation for several decades. As mentioned earlier, in 2010, it decided to build a system using the available technology and built MT@EC which was made operational in 2013. When the technology moved further, the EU decided to make use of the latest technology i.e. NMT. It used the same corpus to develop an NMT-based system, eTranslation in 2017. It is being used by all government agencies, small and medium enterprises, and universities in the members' states and has been operational since 2017. This brings out the point that we should make use of the existing technology and adopt the new technology as and when it becomes available.
Other blogs in this series:
Summary and Abstract
1. Machine Translation: Introduction
2. Machine Translation: The National scenario
3. The National Language Translation Mission
Acknowledgement
While preparing the article, several experts were consulted for their views and suggestion. Their contributions are gratefully acknowledged. In particular, I would like to thank Dr. P. K. Saxena and Prof. G. N. Jha for their suggestions.
Disclaimer
The views presented in the article are those of the author and not the Office of Principal Scientific Adviser to the Government of India. Any comments/suggestions may be sent to the author at sks@meity.gov.in.







